
Hey there! I’m glad you are here.
I was looking around in my old stuff and I just found my old hard-drive. I bought some Bitcoin back when it was worth nothing, and this is the drive that contains my old Bitcoin wallet!
Let’s take a look together.
$ tree .
.
└── bitcoin
└── wallet.txt
It’s all coming back to me now. I bought 10 Bitcoin for a dollar each years ago. I lost my drive after we moved, and after all that time I’ve found it again!
Let’s see what my wallet is worth now.
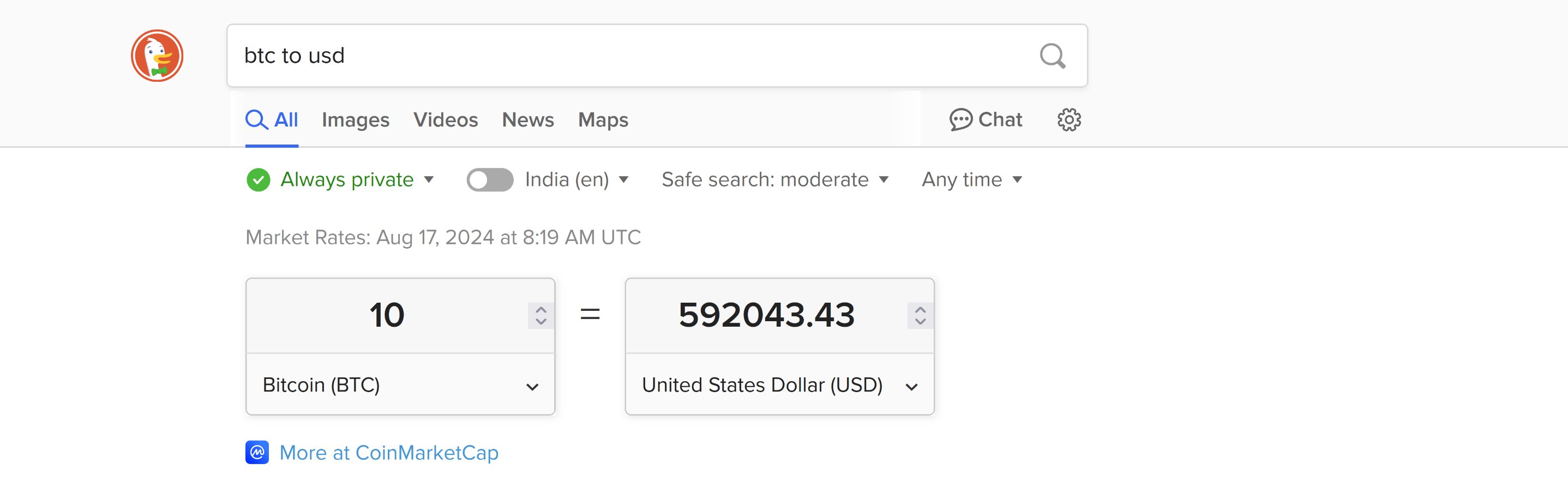
That’s a lot of dollars! My $10 have turned into almost $600,000! I should cash out ASAP before something goes wrong.
Oh, what’s this? I slipped and fell on my keyboard and accidentally created these random files. I’m so clumsy.
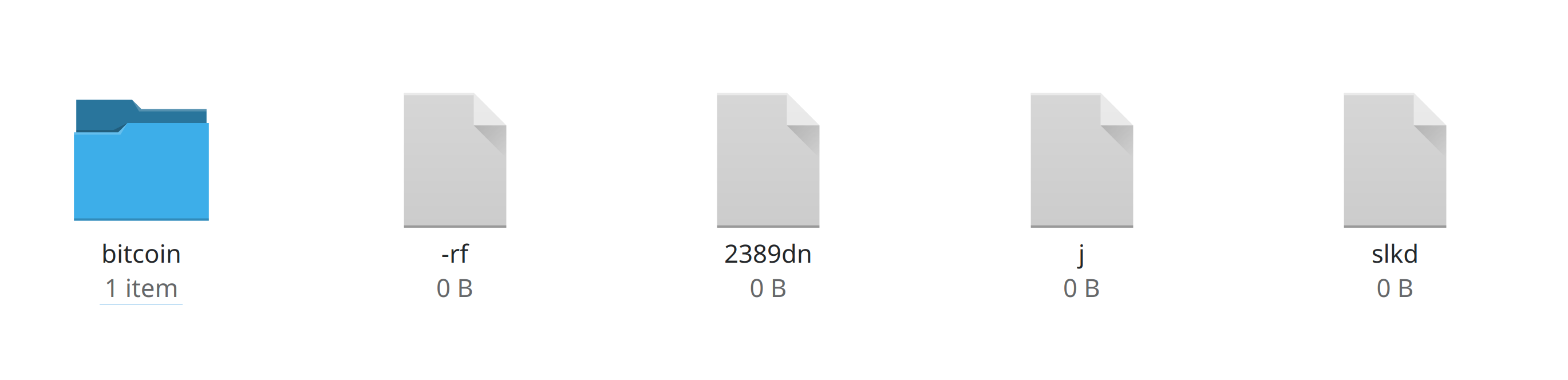
Oh what a bother. But no worries - I can delete all these files with a single Bash command.
$ rm *
I know that Bash will replace the * with the names of all the files and directories
inside the current directory. This includes my bitcoin folder, but that’s alright.
rm only removes files by default, so for my directory I should just get a warning like this:
rm: cannot remove 'bitcoin': Is a directory
This will take a moment. I better do this before I cash out my Bitcoin. There’s no way this can go wrong…
Fallout
My infallible Bash command failed and deleted all my money! But how did this happen?
I’m sure you have noticed already that one of the files I accidentally created was named -rf - that’s right, the filename starts with a hyphen.
The expansion of rm * looks something like this:
$ rm 2389dn bitcoin j -rf slkd
To Bash, that -rf looks an awful lot like the options to -recursively and -forcefully delete stuff.
Because the filename starts with a hypen, the shell thinks that it is a command-line option.
The one thing this command doesn’t delete is the file that caused this in the first place.
$ tree .
.
└── -rf
Collision
A collision of meanings is when a language parser can’t tell the difference between user input and language grammar, and one is misinterpreted as the other.
-rf in the example above is understood and expected by the user to be a filename
(user input), yet the parser thinks that it is a command-line option (language grammar).
Aside
I’ve used “computer languages” in the title of this article because the problem of collisions goes beyond programming or scripting languages.
As you’re going to see in this article, collisions are everywhere.
Shell scripts
This excellent article by David A. Wheeler provides some nice examples for collisions, although the idea of collisions is never mentioned. It also shows how this problem is not exclusive to hyphens or Bash.
I disagree with the conculsion of this article that we should limit filenames to a certain character set. Such solutions are always going to be highly specific to the domain and always incomplete.
Questions like Why does my shell script choke on whitespace or other special characters? are still relevant.
A lot of time and effort has been spent on making sure that your shell scripts work with all external input, and spaces are still as much of a menace as ever.
Comma-separated values
CSV (and other languages belonging to its class, Delimiter-separated values) is perhaps the simplest computer language out there. And even though its grammar is simple, it is not immune to collisions.
If your data contains commas or newlines, you are in trouble.
Aside
Let’s not think about methods of collision mitigation like escaping or quoting. The focus of the article is that this problem exists, and is widespread. We need to have a bigger discussion about collision mitigation strategies, but that is not relevant for this article.
| |
Decimal commas are more popular than you think, and in this simple example are enough to confuse a CSV parser into thinking that the first record contains four fields instead of two.
This doesn’t seem like a huge problem, right? You could just swap out the comma separator with something else; like tabs.
It’s difficult to take collisions seriously in this example, especially because it’s so easy to fix. However, the consequences of collisions can be harsh and expensive.
Injections
Injection attacks are the third most common type of attack in web applications. according to the OWASP Top Ten 2021 report. Injection attacks held an 11-year long streak as the most common attack vector before the 2021 report, after which it was the third.
SQL Injection is perhaps the most widely recognized subset of this attack, but SQL is far from the only language that is vulnerable to injections.
I won’t go into too much detail here, but this Wikipedia article lists several examples of code injection in various domains.
Injection can result in data loss or corruption, lack of accountability, or denial of access. Injection can sometimes lead to complete host takeover.
- That same Wikipedia artice
Complete host takeover? The problem of collisions might be serious after all.
Identifiers
Rules for naming identifiers in programming/scripting languages are extremely restrictive. Most notably, you cannot include a space in an identifier name in even the most permissive and user-friendly languages. Starting a variable name with a number is also generally not allowed.
| |
There is no way for the parser to know if the space belongs to the identifier, or acts as the separator for the next token. To avoid this confusion, language designers created restrictive rules for identifiers.
Have you ever used cls, klass, or some other variant when you wanted to call your variable class in Python?
Have you ever wanted to call your function register() in C or C++?
Programming languages restrict the use of reserved words as identifiers to avoid collisions. Programmers, to avoid using these words, have to find creative ways of conveying the same idea with their identifiers. This frequently leads to confusing and non-intuitive names, and reduces the readability of code.
Why talk about collisions at all?
Collisions are a consequence of the communication medium we use to write code, i.e. plain text. Therefore, the collision problem is baked into most computer languages from the beginning.
Every language solves the collision problem with their own escaping, quoting, or syntax rules. These solutions are specific to the language, whereas the collision problem is essentially universal. By recognizing these characteristics of the communication medium, we have hope of reaching a generalized solution.
It is imperative to talk about collisions before designing new languages because we have a chance of fixing this for every future language, and forever.
Conclusion
I hope this article has made you aware of the collision problem. I hope that after this when you write code, you will be able to see those places yourself where collision subtly changes your behavior.
In my opinion, this problem has been overlooked for too long and the solutions we have sought are deeply flawed because we haven’t recognized the core problem.
In my next post, I will talk about the language design decisions that cause collisions, how we usually work around collisions, and why there will always be collisions (unless…).
Credits
Cover photo by Sergei Starostin on Pexels